Getting started#
dso init – Initialize a project#
dso init initializes a new project in your current directory. In the context of DSO, a project is a structured environment where data science workflows are organized and managed.
To initialize a project use the following command:
# To initialize a project called "test_project" use the following command
dso init test_project --description "This is a test project"
It creates the root directory of your project with all the necessary configuration files for git, dvc, uv and dso itself.
dso create – Add folders or stages to your project#
We consider a stage an individual step in your analysis, usually a script with defined inputs and outputs.
Stages can be organized in folders with arbitrary structures. dso create initializes folders and stages
from predefined templates. We recommend naming stages with a numeric prefix, e.g. 01_ to declare the
order of scripts, but this is not a requirement. Currently, two stage templates have been implemented that
use either a quarto document or bash script to conduct the analysis.
cd test_project
# Let's create a folder that we'll use to organize all analysis steps related to "RNA-seq"
dso create folder RNA_seq
# Let's create first stage for pre-processing
cd RNA_seq
dso create stage 01_preprocessing --template bash --description "Run nf-core/rnaseq"
# Let's create a second stage for quality control
dso create stage 02_qc --template quarto --description "Perform RNA-seq quality control"
Stages have the following pre-defined folder-structure. This folder system aims to make the structure coherent throughout a project for easy readability and navigation. Additional folders can still be added if necessary.
stage
|-- input # contains Input Data
|-- src # contains Analysis Script(s)
|-- output # contains TLF - Outputs generated by Analysis Scripts
|-- report # contains HTML Report generated by Analysis Scripts
Configuration files#
The config files in a project, folder, or stage are the cornerstone of any reproducible analysis, serving as a single point of truth. Additionally, using config files reduces the modification time needed for making project/folder-wide changes.
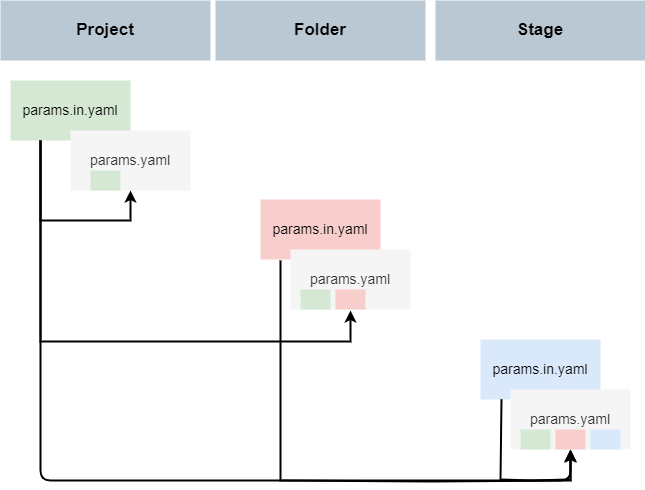
Config files are designed to contain all necessary parameters, input, and output files that should be consistent across the analyses. For this purpose, configurations can be defined at each level of your project in a params.in.yaml file. These configurations are then transferred into the params.yaml files when using dso compile-config.
A params.yaml file consolidates configurations from params.in.yaml files located in its parent directories, as well as from the params.in.yaml file in its own directory. For your analysis, reading in the params.yaml of the respective stage gives you then access to all the configurations.
The following diagram displays the inheritance of configurations:
Writing configuration files#
To define your configurations in the params.in.yaml files, please adhere to the yaml syntax. Due to the implemented configuration inheritance, relative paths need to be resolved within each folder or stage. Therefore, relative paths need to be specified with !path.
An example params.in.yaml can look as follows:
thresholds:
fc: 2
p_value: 0.05
p_adjusted: 0.1
samplesheet: !path "01_preprocessing/input/samplesheet.txt"
metadata_file: !path "metadata/metadata.csv"
file_with_abs_path: "/data/home/user/typical_analysis_data_set.csv"
remove_outliers: true
exclude_samples:
- sample_1
- sample_2
- sample_6
- sample_42
Compiling params.yaml files#
All params.yaml files are automatically generated using:
dso compile-config
Overwriting Parameters#
When multiple params.in.yaml files (such as those at the project, folder, or stage level) contain the same configuration, the value specified at the more specific level (e.g., stage) takes precedence over the value set at the broader level (e.g., project). This makes the analysis adaptable and enhances modifiability across the project.
Implementing a stage#
A stage is a single step in your analysis and usually generates some kind of output data from input data. The input data can also be supplied by previous stages. To create a stage, use the dso create stage command and select either the bash or quarto template as a starting-point.
The essential files of a stage are:
dvc.yaml: The DVC configuration file that defines your data pipelines, dependencies, and outputs.params.yaml: Auto-generated configuration file.params.in.yaml: Modifiable configuration file containing stage-specific configurations.src/<stage_name>.qmd(optional): A Quarto file containing your script that runs the analysis for this stage.
dvc.yaml#
The dvc.yaml file contains information about the parameters, inputs, outputs, and commands used and executes in your stage.
Configuring the dvc.yaml#
Configurations stored in the params.yaml of a stage can be directly used within the dvc.yaml:
stages:
01_preprocessing:
# Parameters used in this stage, defined in params.yaml
params:
- dso
- thresholds
# Dependencies required for this stage, can be defined in the params.yaml (define with ${...})
deps:
- src/01_preprocessing.qmd
- ${file_with_abs_path}
- ${samplesheet}
# Outputs generated by this stage
outs:
- output
- report/01_preprocessing.html
Quarto Stage#
By default, a Quarto stage includes the following cmd in the dvc.yaml file:
# Command to render the Quarto script and move the HTML report to the report folder
cmd:
- dso exec quarto .
Bash Stage#
A Bash stage, by default, does not include an additional script. Bash code can be directly embedded in the dvc.yaml file:
cmd:
- |
bash -euo pipefail << EOF
# add bash code here
EOF